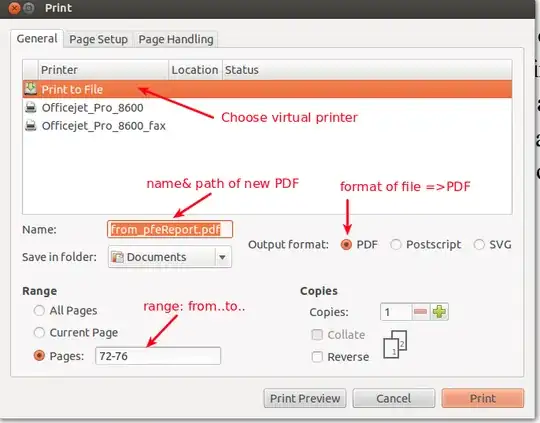
As it turns out, I can do it with imagemagick. If you don't have it, install simply with:
sudo apt-get install imagemagick
Note 1:
I've tried this with a one-page pdf (I'm learning to use imagemagick, so I didn't want more trouble than necessary). I don't know if/how it will work with multiple pages, but you can extract one page of interest with pdftk:
pdftk A=myfile.pdf cat A1 output page1.pdf
where you indicate the page number to be split out (in the example above, A1 selects the first page).
Note 2:
The resulting image using this procedure will be a raster.
Open the pdf with the command display, which is part of the imagemagick suite:
display file.pdf
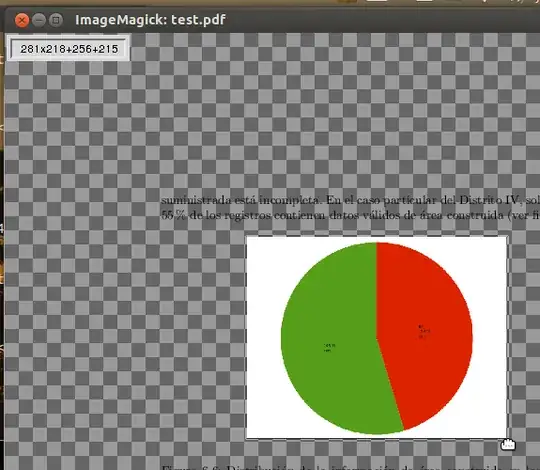
Mine looked like this:
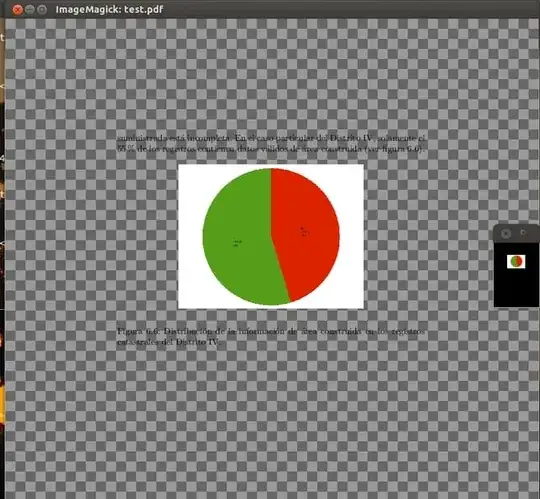
Click on the image to see a full resolution version
Now you click on the window and a menu will pop to the side. There, select Transform | Crop.
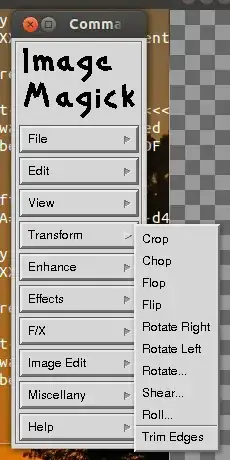
Back in the main window, you can select the area you want to crop by simply dragging the pointer (classic corner-to-corner selection).
Notice the hand-shaped pointer around the image while selecting
This selection can be refined before proceeding to the next step.
Once you are done, take notice of the little rectangle that appears on the upper left corner (see the image above). It shows the dimensions of the area selected first (e.g. 281x218) and second the coordinates of the first corner (e.g. +256+215).
Write down the dimensions of the selected area; you'll need it at the moment of saving the cropped image.
Now, back at the pop menu (which now is the specific "crop" menu), click the button Crop.
Finally, once you are satisfied with the results of cropping, click on menu File | Save
Navigate to the folder where you want to save the cropped pdf, type a name, click the button Format, on the "Select image format type" window select PDF and click the button Select. Back on the "Browse and select a file" window, click the button Save.
Before saving, imagemagick will ask to "select page geometry". Here, you type the dimensions of your cropped image, using a simple letter "x" to separate width and height.
Now, you can do all this perfectly from the command line (the command is convert with option -crop) -- surely it's faster, but you would have to know beforehand the coordinates of the image you want to extract. Check man convert and an example in their webpage.