Maybe there is already some tool that does that, but you can also create a simple script with some screenshot tool and tesseract, as you are trying to use.
Take as an example this script (in my system I saved it as /usr/local/bin/screen_ts):
#!/bin/bash
# Dependencies: tesseract-ocr imagemagick scrot
select tesseract_lang in eng rus equ ;do break;done
# Quick language menu, add more if you need other languages.
SCR_IMG=`mktemp`
trap "rm $SCR_IMG*" EXIT
scrot -s $SCR_IMG.png -q 100
# increase quality with option -q from default 75 to 100
# Typo "$SCR_IMG.png000" does not continue with same name.
mogrify -modulate 100,0 -resize 400% $SCR_IMG.png
#should increase detection rate
tesseract $SCR_IMG.png $SCR_IMG &> /dev/null
cat $SCR_IMG.txt
exit
And with clipboard support:
#!/bin/bash
# Dependencies: tesseract-ocr imagemagick scrot xsel
select tesseract_lang in eng rus equ ;do break;done
# quick language menu, add more if you need other languages.
SCR_IMG=`mktemp`
trap "rm $SCR_IMG*" EXIT
scrot -s $SCR_IMG.png -q 100
# increase image quality with option -q from default 75 to 100
mogrify -modulate 100,0 -resize 400% $SCR_IMG.png
#should increase detection rate
tesseract $SCR_IMG.png $SCR_IMG &> /dev/null
cat $SCR_IMG.txt | xsel -bi
exit
It uses scrot to take the screen, tesseract to recognize the text and cat to display the result. The clipboard version additionally utilizes xsel to pipe the output into the clipboard.
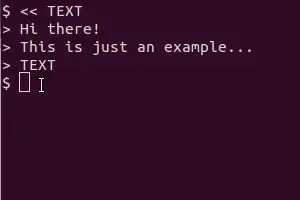
NOTE: scrot, xsel, imagemagick and tesseract-ocr are not installed by default but are available from the the default repositories.
You may be able to replace scrot with gnome-screenshot, but it may take a lot of work. Regarding the output you can use anything that can read a text file (open with Text Editor, show the recognized text as a notification, etc).
GUI version of the script
Here's a simple graphical version of the OCR script including a language selection dialog:
#!/bin/bash
# DEPENDENCIES: tesseract-ocr imagemagick scrot yad
# AUTHOR: Glutanimate 2013 (http://askubuntu.com/users/81372/)
# NAME: ScreenOCR
# LICENSE: GNU GPLv3
#
# BASED ON: OCR script by Salem (http://askubuntu.com/a/280713/81372)
TITLE=ScreenOCR # set yad variables
ICON=gnome-screenshot
# - tesseract won't work if LC_ALL is unset so we set it here
# - you might want to delete or modify this line if you
# have a different locale:
export LC_ALL=en_US.UTF-8
# language selection dialog
LANG=$(yad \
--width 300 --entry --title "$TITLE" \
--image=$ICON \
--window-icon=$ICON \
--button="ok:0" --button="cancel:1" \
--text "Select language:" \
--entry-text \
"eng" "ita" "deu")
# - You can modify the list of available languages by editing the line above
# - Make sure to use the same ISO codes tesseract does (man tesseract for details)
# - Languages will of course only work if you have installed their respective
# language packs (https://code.google.com/p/tesseract-ocr/downloads/list)
RET=$? # check return status
if [ "$RET" = 252 ] || [ "$RET" = 1 ] # WM-Close or "cancel"
then
exit
fi
echo "Language set to $LANG"
SCR_IMG=$(mktemp) # create tempfile
trap "rm $SCR_IMG*" EXIT # make sure tempfiles get deleted afterwards
scrot -s "$SCR_IMG".png -q 100 #take screenshot of area
mogrify -modulate 100,0 -resize 400% "$SCR_IMG".png # postprocess to prepare for OCR
tesseract -l "$LANG" "$SCR_IMG".png "$SCR_IMG" # OCR in given language
xsel -bi < "$SCR_IMG".txt # pass to clipboard
exit
Aside from the dependencies listed above you will need to install the Zenity fork YAD from the webupd8 PPA to make the script work.





{kind=link}
{kind=link}