First of all, the name of backends (devices) have nothing to do with their location! They are all located in US.
Back to your question, as others already mentioned the difference is in the architecture (topology), number of qubits, connectivity, and performance (influenced by various types of errors).
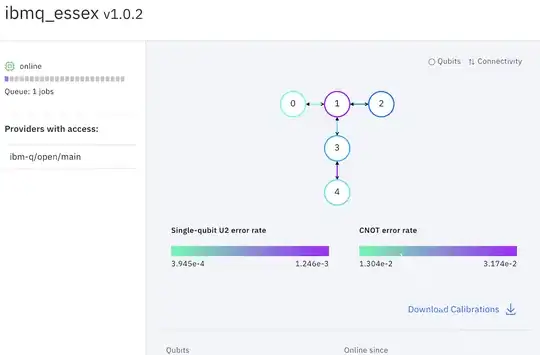
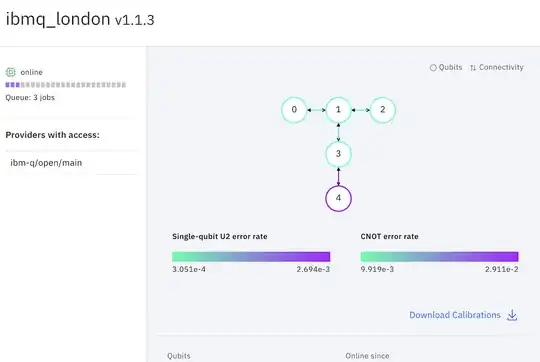
If you click the name of any backend (device) in your IBM_Q Experience dashboard, you'll see detailed information about the error rate for each backend.
For example ibmq_london and ibmq_essex have the same topology and number of quits but qubit_1 in ibmq_london has lower gate error rate compared to the same qubit in ibmq_essex.
That's the reason applying the same gate to same qubits on different backends, results in different output.
Update
is there a particular reason for this, outside of just the inherent "randomness" of QM?
Yes, the reason is the difference in performance between devices.
Many factors influence the performance such as number of qubits, connectivity, gate errors (operational error rates), measurement errors (readout error), retention errors (decoherence and dephasing errors).
Are different IBM pieces of hardware better for different tasks?
As long as the number of qubits doesn't limit your choice of device, you'd always go for devices with higher Quantum volume (higher performance). You can find QV in backend specification for each device.