To be able to explain my question I thought it is probably better to consider the following example: Let's take an environment, where a bridge crane need to lift a barrel from the position "start" and move it to the position "goal" moving along the axes: $X, Y, Z$.
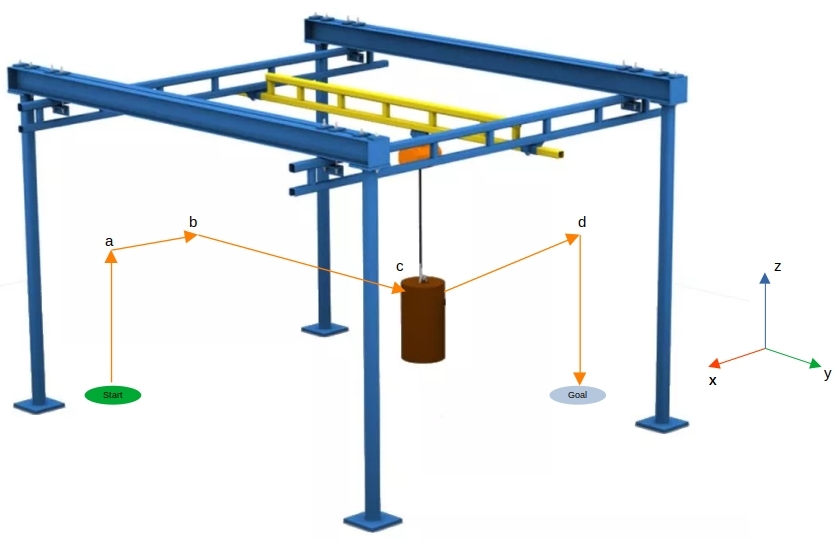
But the movement cannot be straight to the goal. The movement from the start to the goal is based on the presence of obstable in the enviroment and some pratical rules (e.g. the barrel must be lifted first, then horizontally moved and at the end dropped at the goal position).
I'm struggling to figure out, how to train an agent to be able to accomplish such a task. But here I want to share my thoughts:
- At first I thought to use PPO or SAC as model free algorithms and assigning different rewards, when reached the goal and the positions in between (let's call them waypoints) In other words, the agent starts from the start position and gets a reward of +100 points if the agent reaches $a$ in some time. Now... in order to move forward I would need to give a higher reward to $b$. But that means, that the agent will try during the training to reach $b$ directly instead going to $b$ over $a$.
- Even if the issues in the first point are somehow solvable there is the problem, that the agent would learn to reach the goal through the waypoints seen during the training, even if the new environment is now different (obstacles are in different position, the waypoints changed their positions, etc.). So the agent would learn "memorizing" the training environment, without generalization.
What could be the best strategy in such enviroments? Thanks