Linear algebra (Osnabrück 2024-2025)/Part II/Lecture 54
- Stochastic matrices
A real square matrix

is called column stochastic matrix if all entries

and every column sum (that is, for every ), is


The basic interpretation for a column stochastic matrix is the following: There is a set of possible places, spots, positions, vertices in a network, web pages, etc., where someone or something can be with a certain probability (a distribution, a weighting). Such a distribution is described by an -tuple with real non-negative numbers satisfying . This is also called a distribution vector. A column stochastic matrix describes the transition probability in the given network in a certain time segment. The entry is the probability that an object being at the vertex (a visitor of the web page ) moves to the position (goes to the webpage ). The -th standard vector corresponds to the distribution where everything is in the vertex .The -th column of the matrix describes the image of this standard vector under the matrix. In general, for a given distribution , applying the matrix computes the image distribution ; see Exercise 54.1 . A natural question is whether there are distributions that are stationary (stationary distribution, or fixed distribution, or eigendistribution), that is, they are transformed to themselves, or whether there exist periodic distributions, or whether there exist limit distributions, and how to compute them.








A column stochastic -matrix has the form


wit

The characteristic polynomial is

Eigenvalues are and . A stationary distribution is (exclude the cases and for the following computation) given by , because of






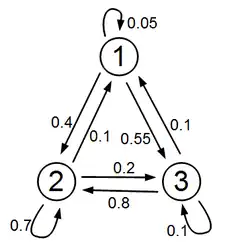
The column stochastic -matrix

transforms the distribution into the distribution . The contribution is transformed to itself, that is, it is a stationary distribution. The distribution is transformed into , and vice versa. It is a periodic distribution, the period length is .






The column stochastic -matrix


transforms the distribution into the distribution


The first standard vector is an eigenvector of the eigenvalue ; every other standard vector, and in fact every distribution vector, is transformed into the first standard vector. The kernel is generated by the vectors , , and does not contain any distribution vector.


Let be a network (a "directed graph“), consisting in a set of vertices, and a set of directed edges, which can exist between the vertices. For example, is the set of all web pages, and there exists an arrow from to , if the web page has a link to the web page . The linking structure can be expressed by the adjacency matrix





where

or by the column stochastic matrix

where

and is the number of links starting at the vertex . This division ensures that the column sum equals (we suppose that there is at least one link starting at any vertex).

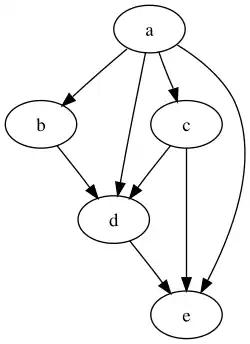
The adjacency matrix, and the column stochastic version of the adjacency matrix of the graph on the right (where we add always self links) are

- Powers of a stochastic matrix
We investigate now the powers of a stochastic matrix with the help of the sum norm and the results of the last lecture.
For an arbitrary vector , we have


Iterative application of this observation shows that Theorem 53.10 (2) is satisfied.

Let
be a real square matrix with non-negative entries. Then is column stochastic if and only if is isometric with respect to the sum norm for vectors with non-negative entries, that is,


holds for all
.
Let be a column stochastic matrix, and

be a vector with non-negative entries. Then

holds. If the described isometric property holds, then it holds in particular for the images of the standard vectors. That means that their sum norm equals . These images are the corresponding columns of the matrix; therefore, all column sums are .
Let be a
column stochastic matrix. Then the following statements hold.- There exists eigenvectors to the eigenvalue .
- If there exists a row such that all its entries are positive, then for every vector
that has a positive and also a negative entry, the estimate
holds.
- If there exists a row such that all its entries are positive, then the eigenspace of the eigenvalue is one-dimensional. There exists an eigenvector where all entries are no-negative; in particular, there is a uniquely determined stationary distribution.

- The transposed matrix is row stochastic; therefore, it has an eigenvector to the eigenvalue . Due to Theorem 23.2 , the characteristic polynomial of the transposed matrix has a zero at . Because of Exercise 23.19 , this also holds for the matrix we have started with. Hence, has an eigenvector to the eigenvalue .
- We now assume also that all entries of the -th row are positive, and let
denote a vector with
(at least)
a positive and a negative entry. Then
holds.
- As in the proof of (2), let all entries of the -th row be positive. For any eigenvector to the eigenvalue , according to (2), either all entries are non-negative, or non-positive. Hence, for such a vector, because of , its -th entry is not . Let be such eigenvectors. Then belongs to the fixed space. However, the -th component of this vector equals ; therefore, it is the zero vector. This means that and are linearly dependent. Therefore, this eigenspace is one-dimensional. Because of (2), there exists an eigenvector to the eigenvalue with non-negative entries. By normalizing, we get a stationary distribution.








We consider the column stochastic -matrix


here, all entries of the first row are positive. Due to Lemma 54.8 , there exists a unique eigendistribution. In order to determine this distribution, we compute the kernel of

This kernel is generated by , and the stationary distribution is


For the column stochastic -matrix

the eigenspace to the eigenvalue equals ;, it is two-dimensional. This shows that the conclusion of Lemma 54.8 does not hold even when there exists a column (but not a row) with strictly positive entries.

Let be a column stochastic matrix, fulfilling the property that there exists a row in which all entries are positive. Then for every distribution vector with , the sequence converges to the uniquely determined stationary distribution
of .
Let be the stationary distribution, which is uniquely determined because of Lemma 54.8 (3). We set


This is a linear subspace of of dimension . Due to Lemma 54.8 (2), has only non-negative entries; therefore, it does not belong to . Because of




is invariant under the matrix . Hence,

is a direct sum decomposition into invariant linear subspaces. For every with , we have



due to Lemma 54.8 (2). The sphere of radius is compact with respect to every norm; therefore, the induced maximum norm of is smaller than . Because of Lemma 53.8 and Theorem 53.6 , the sequence converges for every to the zero vector.


Let now be a distribution vector; because of

we can write

with . Because of

and the reasoning before, this sequence converges to .
In the situation of Lemma 54.8 , we can find the eigendistribution by solving a system of linear equations. If we are dealing with a huge matrix (think about vertices), then such a computation time-consuming. Often, it is not necessary to know the eigendistribution precisely; it is enough to know a good approximation. For this, we may start with an arbitrary distribution, and we compute finitely many iterations. Because of Theorem 54.11 , we know that this method gives arbitrarily good approximations of the eigendistribution. For example, a search engine for the web generates for search item an ordered list of web pages where this search item occurs. How does this ordering arise? The true answer is, at least for the first entries, that it depends on how much someone has paid. Despite of this, it is a natural approach, and this is also the basis for the Page ranks, to consider the numerical ordering in the eigendistribution. The first entry is the one where most people would "finally“ end up when they follow with the same probability any possible link. This movement is modelled[1] by the stochastic matrix described in Example 54.5 .

The numerical difference between finding an exact solution of a system of linear equations to determine an eigenvector, and the power method, can be grasped in the following way. Let an -matrix be given. The elimination process needs in order to eliminate the first variable in equations, multiplications (here, we do not consider the easier additions); therefore, the seize of the multiplications in the complete elimination process is


For the evaluation of the matrix at a vector, multiplications are necessary. If we want to compute iterations, we need operations. Hence, if is substantially smaller than , then thetotal expenditure is substantially smaller.


- Footnotes
- ↑ Modelling means in (in particular, applied) mathematics the process to understand phenomena of the real world with mathematical tools. We model physical processes, weather phenomena, transactions in finance, etc.
| << | Linear algebra (Osnabrück 2024-2025)/Part II | >> PDF-version of this lecture Exercise sheet for this lecture (PDF) |
|---|