In stim's error corretion example here, and in pymatching's toric code example here, the threshold calculation involves taking a number of rounds that scales as the code distance. Why is that the right way to do it?
To test what's going on if I try to do it some other way, calculated the threshold with a fixed number of rounds, yet much larger than the distance, and I get something that behaves reasonably until some "pseudo threshold" value, and then the errors seem to more or less track each other. How can we explain this behavior?
Here's an example of a surface code with rounds = 3 * distance as in the stim example:
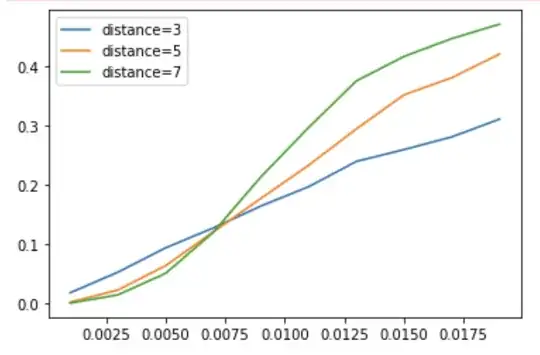
and here's one with rounds=20:
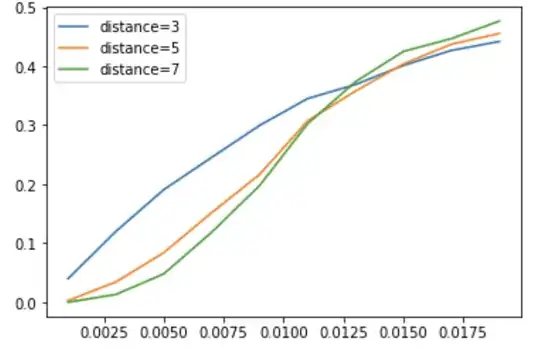
The x axis are physical (2 qubit gate) error rates, and the y axis is logical error rate
BTW, I have a vague feeling that this is somehow related to this question.
