https://meta.stackexchange.com/q/388551/178179 mentions that SE will force some firms to pay to be allowed to train an AI model on the SE data dump (CC BY-SA licensed) and make a commercial use of it without distributing the model under CC BY-SA.
This makes me wonder: Is it illegal for a firm to train an AI model on a CC BY-SA 4.0 corpus and make a commercial use of it without distributing the model under CC BY-SA?
I found https://creativecommons.org/2021/03/04/should-cc-licensed-content-be-used-to-train-ai-it-depends/:
At CC, we believe that, as a matter of copyright law, the use of works to train AI should be considered non-infringing by default, assuming that access to the copyright works was lawful at the point of input.
Is that belief correct?
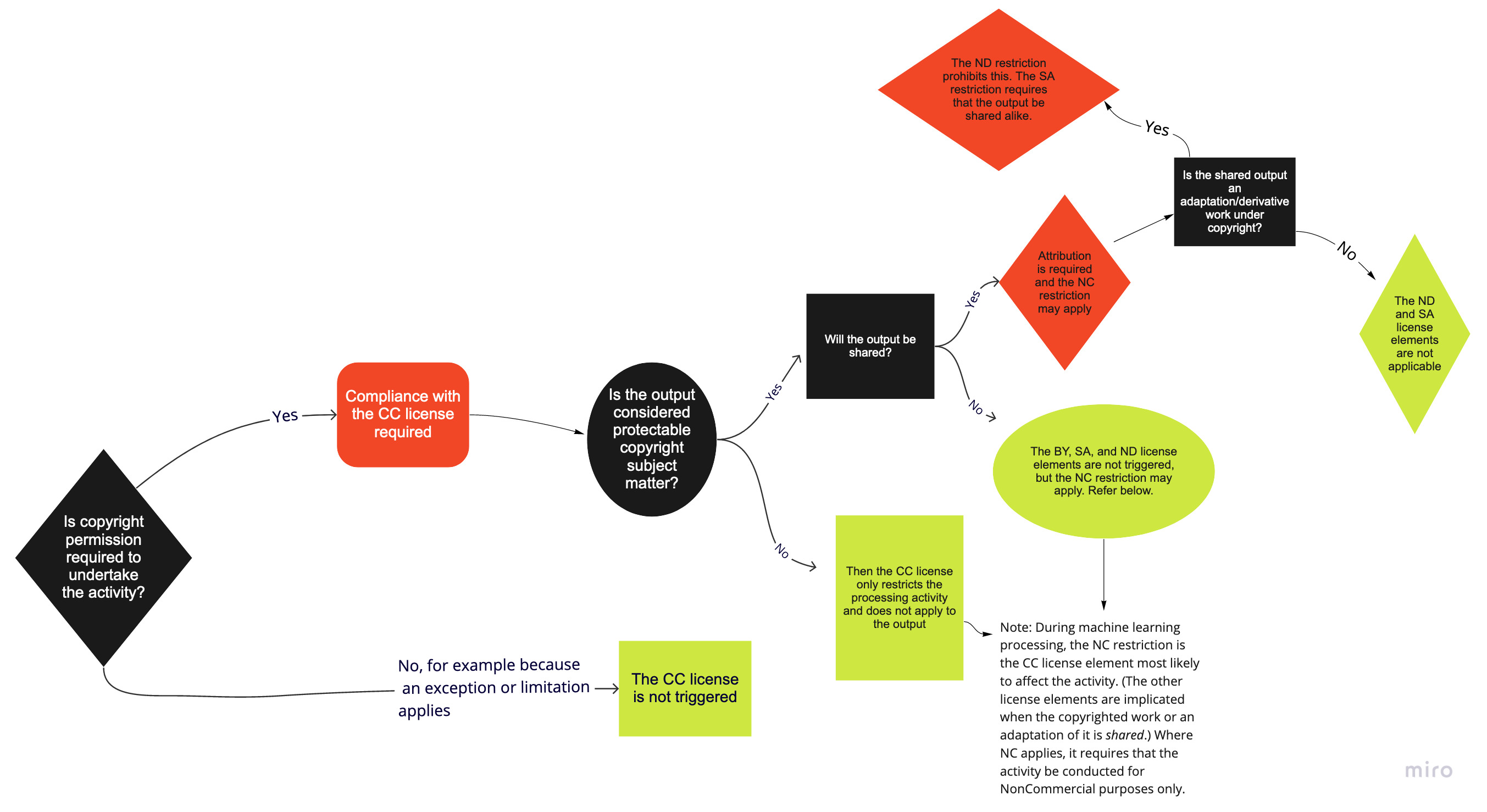
More specifically to the share-alike clause in CC licenses, from my understanding of https://creativecommons.org/faq/#artificial-intelligence-and-cc-licenses, it is legal for a firm to train an AI model on a CC BY-SA 4.0 corpus and make a commercial use of it without distributing the model under CC BY-SA, unless perhaps if the output is shared (2 questions: Is the output of an LLM considered an adaptation or derivative work under copyright? Does the "output" in the flowchart below mean LLM output in the case a trained LLM?).