Preamble
You are looking for a PDF sandwich, i.e. a scanned PDF with an invisible layer of text (or a layer of text which is simply placed behind the picture of each page).
There are several ways to create one. I will use the paper Term Weighting Approaches in Automatic Text Retrieval as an example of a document that needs OCR.
The pdfsandwich command
First of all, install this tool from the repositories:
sudo apt install pdfsandwich
Then you can just run it on your PDF file and wait:
pdfsandwich document.pdf
In the past, this method was not very precise, especially w.r.t. text positioning. It seems that now things got a lot better. Example from the PDF:
Abstract–The experimental evidence accumulated over the past 20 years indicates that
If you highlight the text in Evince, black boxes are shown.
PDF-XChange Viewer
This is a freeware, Windows-only program that works perfectly under Wine if you use the 32-bit version in a 32-bit Wine prefix. For this, I suggest using PlayOnLinux because it's very easy to select the latest Wine version and the fact that you want a 32-bit prefix.
Once installed, you can run it and select the OCR icon on the toolbar:
The output is usually very good and the text placement is precise. Example from the PDF:
Abstract--The experimental evidence accumulated over the past 20 years indicates that
If you highlight the text in Evince, the text is shown in a sans-serif font.
OCR.space
This is actually a web service. Go to ocr.space and select your file and language, then check the "Create searchable PDF with invisible text layer" option. Push the button and wait until the document is uploaded and converted.
Unfortunately, there is a bug for horizontal pages and they do not get rendered correctly in the output. I have notified the authors of this and they have acknowledged the problem.
OCRmyPDF
I am basing this part on what I posted in this answer on Super User.
OCRmyPDF is a multiplatform program written in Python, based on Ghostscript, Tesseract and Unpaper. From the docs:
What OCRmyPDF does
OCRmyPDF analyzes each page of a PDF to determine the colorspace and
resolution (DPI) needed to capture all of the information on that page
without losing content. It uses Ghostscript to rasterize the page, and
then performs on OCR on the rasterized image to create an OCR “layer”.
The layer is then grafted back onto the original PDF.
It can be easily installed on Debian and Ubuntu derivatives:
apt-get install ocrmypdf
You might need to install additional dictionaries for Tesseract, depending on the language you want to use. You can find a list of package names here (for macOS but they are the same on Ubuntu).
Usage is very simple and I suggest you use the optional -d (deskew) and -c (clean) parameters for better results. It will straighten every page and clean up small dots/imperfections before running the OCR process.
You can (and should) provide the language with -l.
Here's an example taken from this skewed document written in Italian:
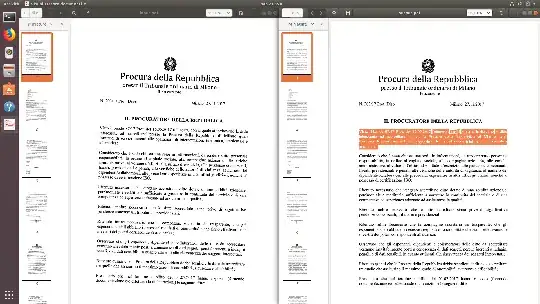
The command I used was:
ocrmypdf -l ita -d -c input.pdf output.pdf
PDF24 hosts a free web-based version of OCRmyPDF that can be used without limitations.


