Is there any way to convert a web page and its sub pages into one PDF file?
Asked
Active
Viewed 1.3k times
1 Answers
18
Save a list of Web pages as PDF file
First install
wkhtmltopdfconversion tool (this tool requires desktop environment; source):sudo apt install wkhtmltopdfThen create a file that contains a list of URLs of multiple target web pages (each on new line). Let's call this file
url-list.txtand let's place it in~/Downloads/PDF/. For example its content could be:https://askubuntu.com/users/721082/tarek https://askubuntu.com/users/566421/pa4080And then run the next command, that will generate a PDF file for each site URL, located into the directory where the command is executed:
while read i; do wkhtmltopdf "$i" "$(echo "$i" | sed -e 's/https\?:\/\///' -e 's/\//-/g' ).pdf"; done < ~/Downloads/PDF/url-list.txtThe result of this command - executed within the directory
~/Downloads/PDF/- is:~/Downloads/PDF/$ ls -1 *.pdf askubuntu.com-users-566421-pa4080.pdf askubuntu.com-users-721082-tarek.pdfMerge the output files by the next command, executed in the above directory (source):
gs -dBATCH -dNOPAUSE -q -sDEVICE=pdfwrite -dPDFSETTINGS=/prepress -sOutputFile=merged-output.pdf $(ls -1 *.pdf)The result is:
~/Downloads/PDF/$ ls -1 *.pdf askubuntu.com-users-566421-pa4080.pdf askubuntu.com-users-721082-tarek.pdf merged-output.pdf
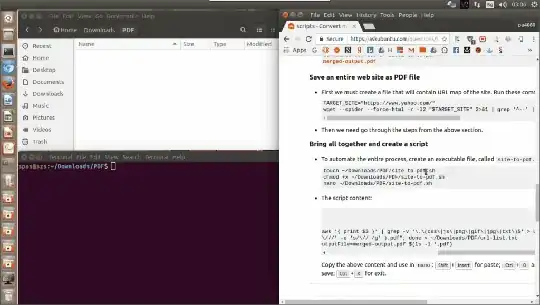
Save an entire Website as PDF file
First we must create a file (
url-list.txt) that contains URL map of the site. Run these commands (source):TARGET_SITE="https://www.yahoo.com/" wget --spider --force-html -r -l2 "$TARGET_SITE" 2>&1 | grep '^--' | awk '{ print $3 }' | grep -v '\.\(css\|js\|png\|gif\|jpg\)$' > url-list.txtThen we need go through the steps from the above section.
Create a script that will Save an entire Website as PDF file (recursively)
To automate the process we can bring all together in a script file.
Create an executable file, called
site-to-pdf.sh:mkdir -p ~/Downloads/PDF/ touch ~/Downloads/PDF/site-to-pdf.sh chmod +x ~/Downloads/PDF/site-to-pdf.sh nano ~/Downloads/PDF/site-to-pdf.shThe script content is:
#!/bin/sh TARGET_SITE="$1" wget --spider --force-html -r -l2 "$TARGET_SITE" 2>&1 | grep '^--' | awk '{ print $3 }' | grep -v '\.\(css\|js\|png\|gif\|jpg\|txt\)$' > url-list.txt while read i; do wkhtmltopdf "$i" "$(echo "$i" | sed -e 's/https\?:\/\///' -e 's/\//-/g' ).pdf"; done < url-list.txt gs -dBATCH -dNOPAUSE -q -sDEVICE=pdfwrite -dPDFSETTINGS=/prepress -sOutputFile=merged-output.pdf $(ls -1 *.pdf)Copy the above content and in
nanouse: Shift+Insert for paste; Ctrl+O and Enter for save; Ctrl+X for exit.Usage:

The answer to the original question:
Convert multiple PHP files to one PDF (recursively)
First install the package
enscript, which is a 'regular file to pdf' conversion tool:sudo apt update && sudo apt install enscriptThen run the next command, that will generate file called
output.pdf, located into directory where the command is executed, which will contains the content of allphpfiles within/path/to/folder/and its sub-directories:find /path/to/folder/ -type f -name '*.php' -exec printf "\n\n{}\n\n" \; -exec cat "{}" \; | enscript -o - | ps2pdf - output.pdfExample, from my system, that generated this file:
find /var/www/wordpress/ -type f -name '*.php' -exec printf "\n\n{}\n\n" \; -exec cat "{}" \; | enscript -o - | ps2pdf - output.pdf
pa4080
- 30,621