If you are ready to use CLI, the following command should work for you:
diff --brief -r backup/ documents/
This will show you the files that are unique to each folder. If you want you can also ignore filename cases with the --ignore-file-name-case
As an example:
ron@ron:~/test$ ls backup/
file1 file2 file3 file4 file5
ron@ron:~/test$ ls documents/
file4 file5 file6 file7 file8
ron@ron:~/test$ diff backup/ documents/
Only in backup/: file1
Only in backup/: file2
Only in backup/: file3
Only in documents/: file6
Only in documents/: file7
Only in documents/: file8
ron@ron:~/test$ diff backup/ documents/ | grep "Only in backup"
Only in backup/: file1
Only in backup/: file2
Only in backup/: file3
In addition, if you want to report only when the files differ (and not report the actual 'difference'), you can use the --brief option as in:
ron@ron:~/test$ cat backup/file5
one
ron@ron:~/test$ cat documents/file5
ron@ron:~/test$ diff --brief backup/ documents/
Only in backup/: file1
Only in backup/: file2
Only in backup/: file3
Files backup/file5 and documents/file5 differ
Only in documents/: file6
Only in documents/: file7
Only in documents/: file8
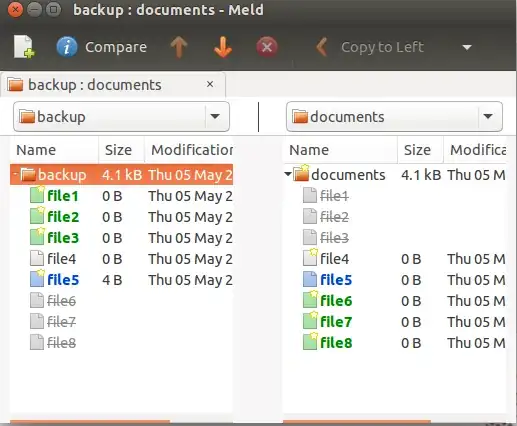
There are several visual diff tools such as meld that can do the same thing. You can install meld from the universe repository by:
sudo apt-get install meld
and use its "Directory comparison" option. Select the folder you want to compare. After selection you can compare them side-by-side:
fdupes is an excellent program to find the duplicate files but it does not list the non-duplicate files, which is what you are looking for. However, we can list the files that are not in the fdupes output using a combination of find and grep.
The following example lists the files that are unique to backup.
ron@ron:~$ tree backup/ documents/
backup/
├── crontab
├── dir1
│ └── du.txt
├── lo.txt
├── ls.txt
├── lu.txt
└── notes.txt
documents/
├── du.txt
├── lo-renamed.txt
├── ls.txt
└── lu.txt
1 directory, 10 files
ron@ron:~$ fdupes -r backup/ documents/ > dup.txt
ron@ron:~$ find backup/ -type f | grep -Fxvf dup.txt
backup/crontab
backup/notes.txt
