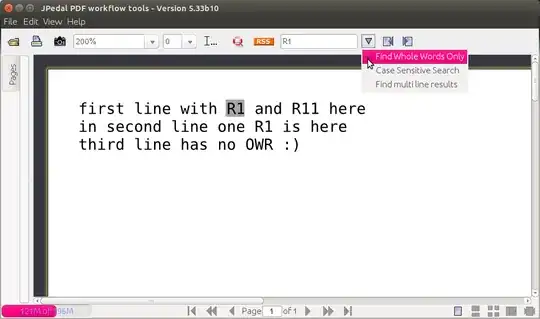
I am an electronics engineer and I regularly view PDF schematics. Often I encounter the scenario where I would like to search the schematic for a component, e.g. "R1"
The problem is that searching for "R1" matches all the R[tens] and R[hundreds] on the schematic as well. So I would like to be able to use a regex in my search, or at least have tighter control of the search (e.g. search whole word only).
Has anyone here found a good PDF tool on Ubuntu which supports these features?
 ) to search for whole word.
) to search for whole word.