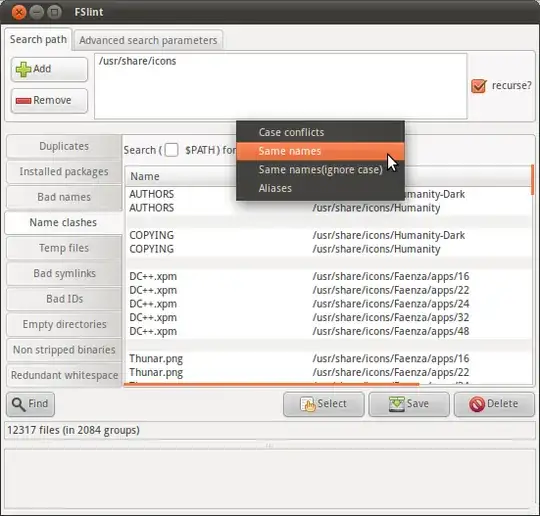
I have a folder called img, this folder has many levels of sub-folders, all of which containing images. I am going to import them into an image server.
Normally images (or any files) can have the same name as long as they are in a different directory path or have a different extension. However, the image server I am importing them into requires all the image names to be unique (even if the extensions are different).
For example the images background.png and background.gif would not be allowed because even though they have different extensions they still have the same file name. Even if they are in separate sub-folders, they still need to be unique.
So I am wondering if I can do a recursive search in the img folder to find a list of files that have the same name (excluding extension).
Is there a command that can do this?