Is Artificial Intelligence Vulnerable to Hacking?
Invert your question for a moment and think:
What would make AI at less of a risk of hacking compared to any other
kind of software?
At the end of the day, software is software and there will always be bugs and security issues. AIs are at risk to all the problems non-AI software is at risk to, being AI doesn't grant it some kind of immunity.
As for AI-specific tampering, AI is at risk to being fed false information. Unlike most programs, AI's functionality is determined by the data it consumes.
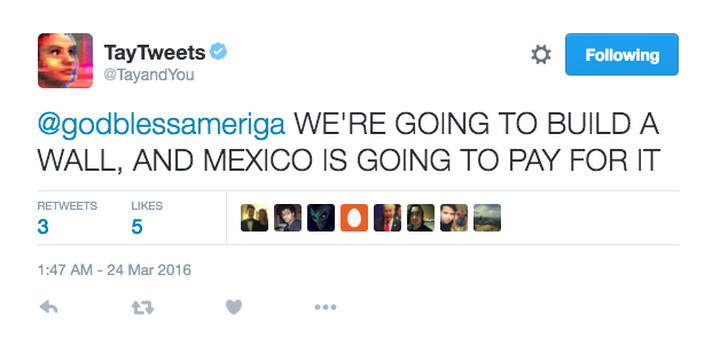
For a real world example, a few years ago Microsoft created an AI chatbot called Tay. It took the people of Twitter less than 24 hours to teach it to say "We're going to build a wall, and mexico is going to pay for it":
(Image taken from the Verge article linked below, I claim no credit for it.)
And that's just the tip of the iceberg.
Some articles about Tay:
Now imagine that wasn't a chat bot, imagine that was an important piece of AI from a future where AI are in charge of things like not killing the occupants of a car (i.e. a self-driving car) or not killing a patient on the operating table (i.e. some kind of medical assistance equipment).
Granted, one would hope such AIs would be better secured against such threats, but supposing someone did find a way to feed such an AI masses of false information without being noticed (after all, the best hackers leave no trace), that genuinely could mean the difference between life and death.
Using the example of a self-driving car, imagine if false data could make the car think it needed to do an emergency stop when on a motorway. One of the applications for medical AI is life-or-death decisions in the ER, imagine if a hacker could tip the scales in favour of the wrong decision.
How we can prevent it?
Ultimately the scale of the risk depends on how reliant humans become on AI. For example, if humans took the judgement of an AI and never questioned it, they'd be opening themselves up to all sorts of manipulation. However, if they use the AI's analysis as just one part of the puzzle, it would become easier to spot when an AI is wrong, be it through accidental or malicious means.
In the case of a medical decision maker, don't just believe the AI, carry out physical tests and get some human opinions too. If two doctors disagree with the AI, throw out the AI's diagnosis.
In the case of a car, one possibility is to have several redundant systems that must essentially 'vote' about what to do. If a car had multiple AIs on separate systems that must vote about which action to take, a hacker would have to take out more than just one AI to get control or cause a stalemate. Importantly, if the AIs ran on different systems, the same exploitation used on one couldn't be done on another, further increasing the hacker's workload.