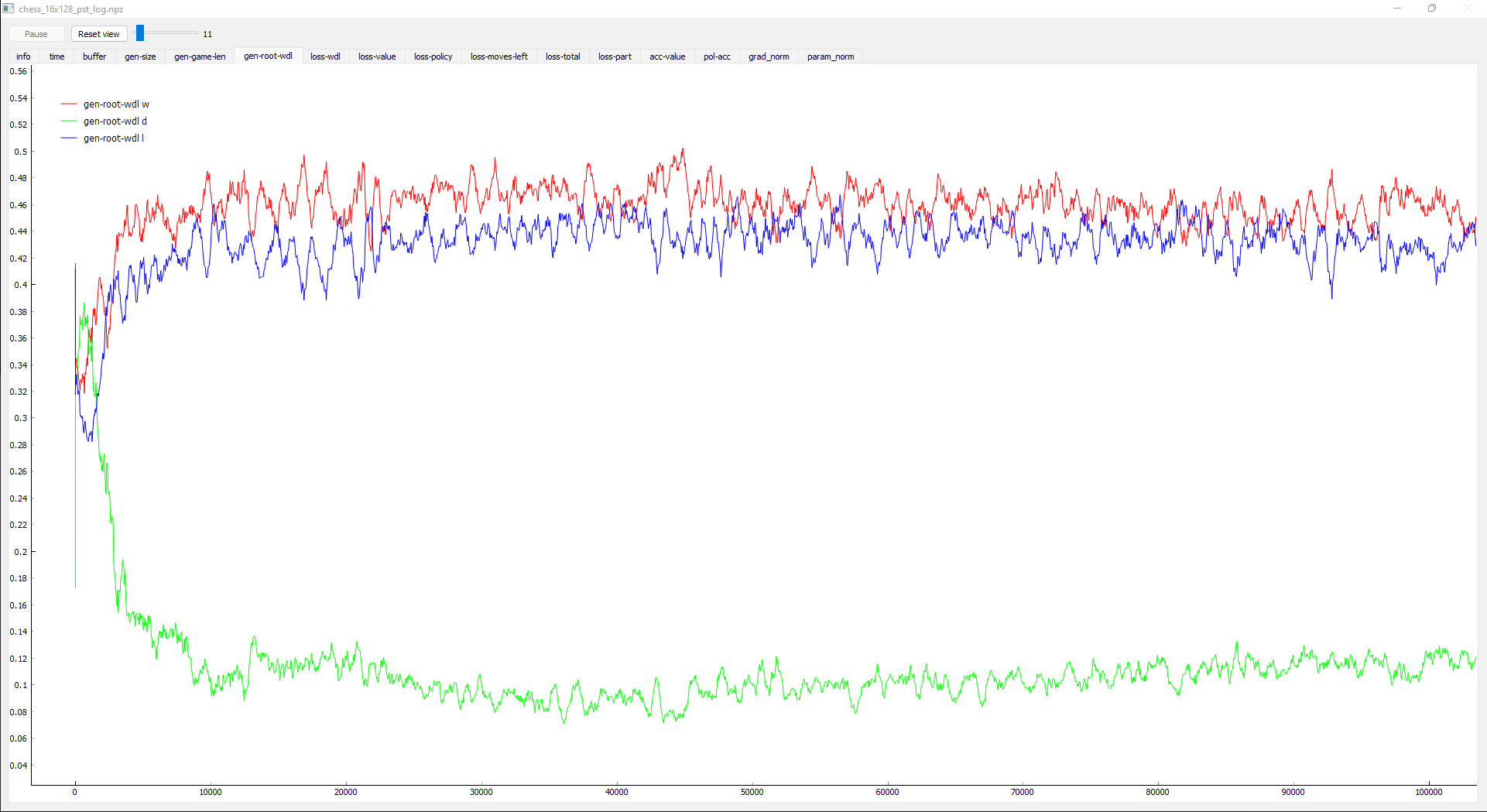
I am experimenting with a self-programmed version of AZ Chess following the described methodology in the official paper. I am experiencing that at the beginning of the self-play (when the ANN weights are is still randomly initialized) a very high portion of all games end with a "draw" (ca. 97% of all games). This is not surprising because if two pure random players play against each other, it is very unlikely that white or black achieve a win/lose. As a result, ca. 97% of all board states visited during the sell-play are trained towards a target value of 0 (instead towards +1/-1 for white to win/lose). This means that there is very litte training data (3% of all training data generated via self-play) that helps the ANN to learn how to win and to get stronger.
Does anyone know how DeepMind has overcome this problem? I have found nothing about this in the www.