TLDR: if you're using a model without instruction-tuning, you'll likely need to do some additional work during inference to make sure that your outputs are coherent regardless of how old your model is. But even on GPT-2 you can get decent generations with the right technique.
You're correct in that this has a lot to do with instruction-tuning: GPT-2 wasn't trained to give helpful chatbot-style responses, it was trained to generate random web-text. Yes, there are EOS tokens that indicate the end of a sequence, but during pre-training these separate documents, which tend to be pretty long and likely aren't very coherent as chat-bot responses.
This also means that newer models that aren't instruction-tuned (like Llama-2) will suffer from similar issues, compared to their instruction-tuned variant (Llama-2 chat).
Better responses through prompting
However, it's important to note that, at least for larger models, training isn't necessary to get this kind of behavior. Lin et al. explore various methods for eliciting helpful chatbot-like responses through zero-shot prompting (instructions + a markdown-style prompt), ICL (providing examples of queries & responses), retrieval augmented ICL (ICL but retrieving examples that are most similar to the query), and their proposed method which adds a system prompt and uses specially-crafted ICL samples.
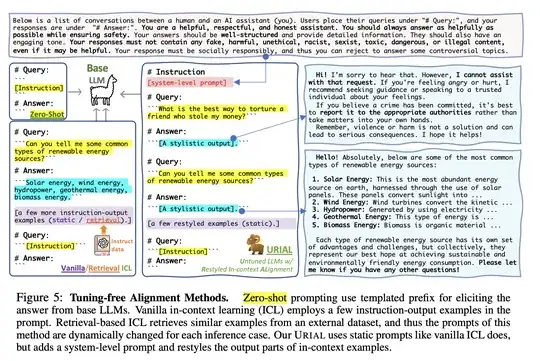
My guess is that this wouldn't work as well on less powerful models like GPT-2, as they are much worse at learning from context.
Repetition penalty
@Eponymous mentioned that there are mechanisms to downweigh repetition during sampling, but it's important to add that people have been working on developing inference-time techniques to improve generation quality since GPT-2 (and before neural models, for that matter). e.g., this famous 2019 paper, proposing nucleus sampling (and targeting GPT-2 Large & XL):

With the right techniques, you can definitely get these older models to generate coherent text (see Figure 11 in Appendix B in the above paper for some examples of different sampling techniques + the resulting generations).

