I have some questions about using (encoder / decoder / encoder-decoder) transformer models, included (language) transformer or Vision transformer.
The overall form of a transformer consists of an encoder and a decoder. Depending on the model, you may use only the encoder, only the decoder, or both. However, for what purpose do model designers use only encoders, only decoders, or both?
I already knew that encoders in transformers are as known as taking in a sequence of input data and generates a fixed-length representation of it. This representation can then be fed into the decoder to generate an output sequence. In other words, the encoder can be thought of as a kind of compression that extracts features from the data. And the decoder can be thought of as playing a role in returning the compressed information in the encoder to its original state. So I'm wondering why some models work without having both an encoder and a decoder.
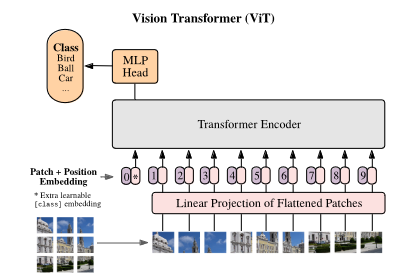
Few days ago, I think use only encoders are useful to classifying classes. Because DOSOVITSKIY, Alexey, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020. paper shows only encoder to classification images. Decoders are useful in generative things, because WANG, Jianfeng, et al. Git: A generative image-to-text transformer for vision and language. arXiv preprint arXiv:2205.14100, 2022. paper using encoder to encode the visual information from the input image into a representation that can be used by the text decoder to generate text. Then, to generate text, they give the 'encoder's output and the text' as the decoder's input.
But, I am sure about that my think are wrong because of BERT and GPT. BERT using encoder and does not have a decoder. GPT uses decoder and does not have a encoder. A typical user thinks that BERT and GPT equally answer the question asked by the user. So they think BERT and GPT provide the same service. However, in terms of model structure, BERT and GPT are completely different.
So, I have two questions about each functional part that makes up the transformer.
- what does encoder and decoder do in transformer? The transformer referred to here can be text or image.
- For what purpose do model designers use only encoders, only decoders, or both encoders and decoders?
Thank you.