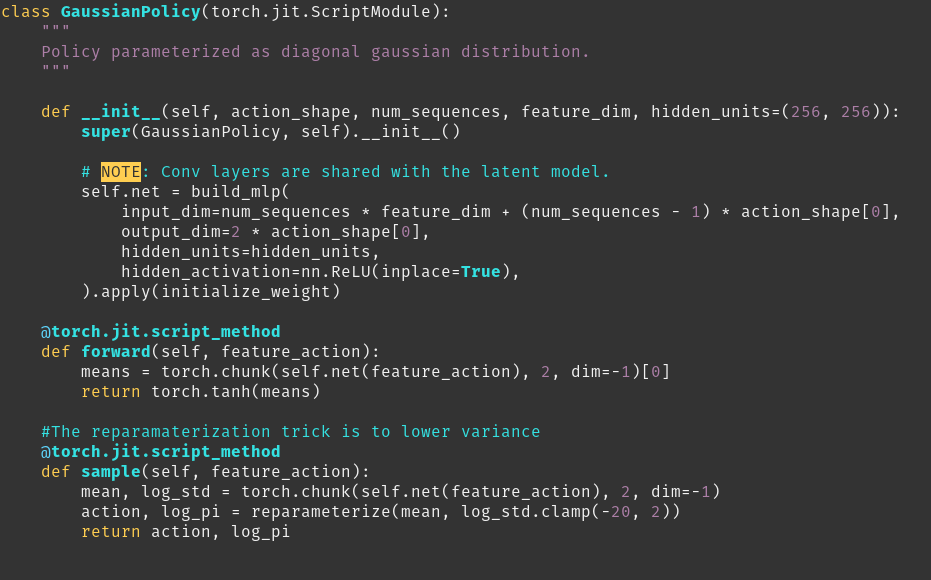
In the Soft Actor Critic Paper (found here https://arxiv.org/pdf/1801.01290.pdf), they use a neural network to approximate a diagonal gaussian distribution. In the sample function you can see that it has a function called reparameterize. As you can see in the reparameterize function, we use a tanh function to squash the action bound between -1 and 1. So why is it that we clamp the standard deviation between -20 and 2. I have read both Soft Actor Critic papers and can't find why we do this. Is there something about the normal distribution that would make that range of clamping of the std more desirable? Does bounding the range of the std help with convergence. Is there a paper you my recommend that would help with this answer? This is my first post here so if you need more information please let me know.