While looking into the vanishing gradient problem, I came across a paper (https://ieeexplore.ieee.org/abstract/document/9336631) that used artificial derivatives in lieu of the real derivatives. For a visualization, see the attached image: 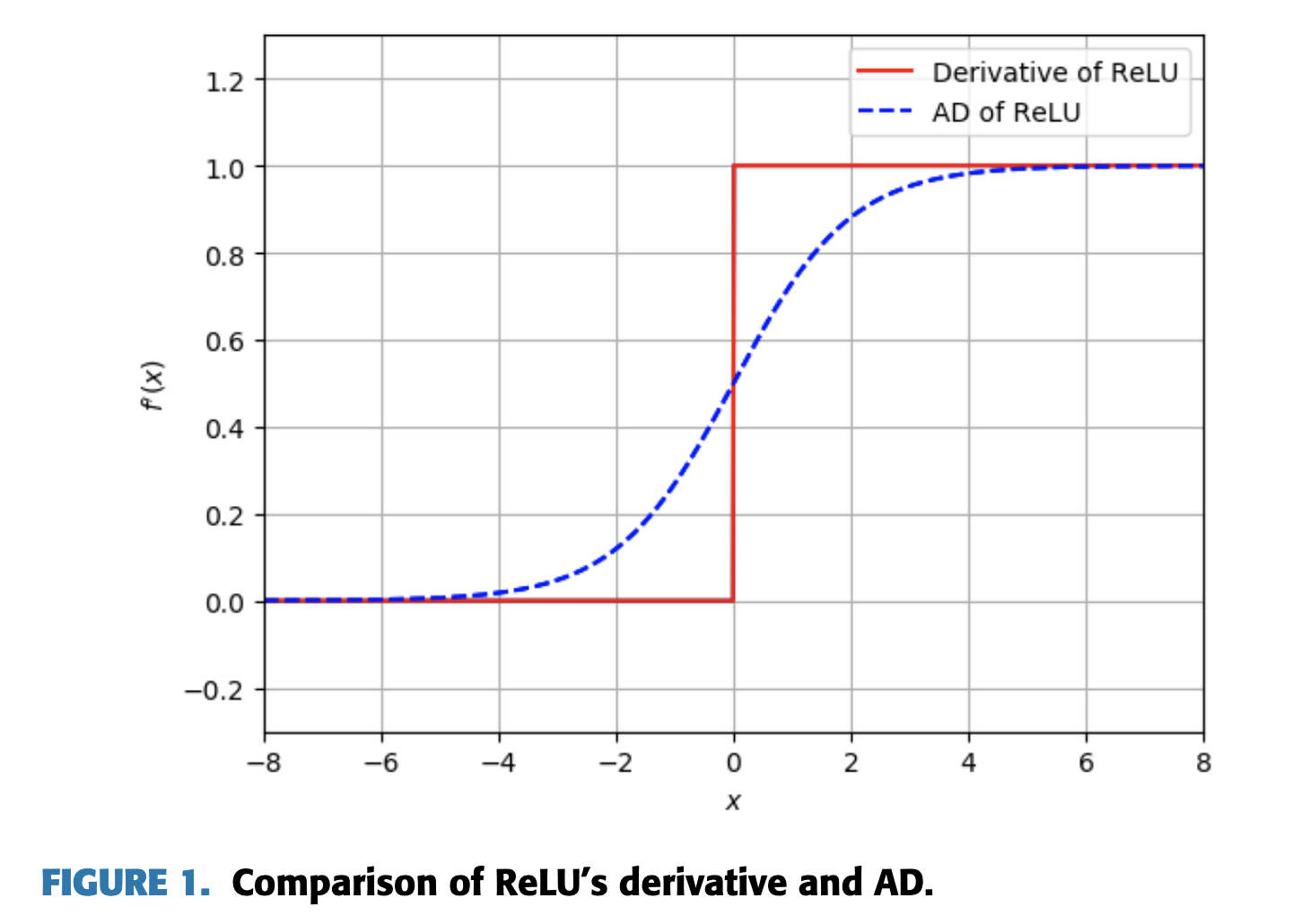
As you can see, the artificial derivative of the ReLU is the sigmoid function, which smoothes out the derivative to circumvent the dying ReLU problem. The authors apply similar smoothing operations for other activation functions such as the sigmoid. This idea seems pretty convincing, and it surprises me that it has not been used thus far, especially considering there is no additional computational cost in replacing the derivatives, as the authors claim. So why is it that vanishing gradients have not been addressed in this way in conventional deep learning frameworks such as Pytorch or Tensorflow?