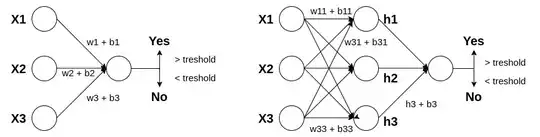
The quick answer is yes. The implementation of sklearn use both a bias for each weight and a final threshold, by default set to 0.5
It sounds to me though that you don't have a clear idea about the purpose of the threshold in the first place, so let's elaborate more on that.
why do we use a threshold
A perceptron, and any other type of model, return continuous values. For some tasks (e.g. regression) we can compute error directly on these continuous values, but for other tasks (e.g. classification) we need to convert these values into discrete values, usually binary, which tell us if the model is predicting a yes or a no for a specific node. The threshold serves precisely for this purpose. We apply it to the very last probabilities returned by a model to convert them into discrete outputs (and I stress out probabilities, not logits, so you need to apply first either sigmoid of softmax).
when do we modify the threshold
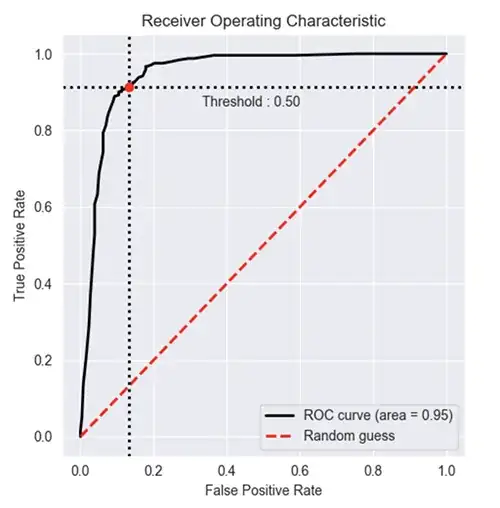
The only moment in which is reasonable to change the threshold is after training. And the reason to do so is that we want to test if there are values different from 0.5 that lead to better metrics score. Usually this is performed using the ROC curve. i.e. we compute the amount of false positives an false negatives for different thresholds and we check what threshold lead to the highest AUC score (the red one in the plot, which maximize the ROC area).
But there is no point in using a different threshold from 0.5 during training. And there is no point in associating multiple threshold to each bias in a model. The only reason why the threshold is used is to discretize continuous values ad turn them into final predictions.