Adding BatchNorm layers improves training time and makes the whole deep model more stable. That's an experimental fact that is widely used in machine learning practice.
My question is - why does it work?
The original (2015) paper motivated the introduction of the layers by stating that these layers help fixing "internal covariate shift". The rough idea is that large shifts in the distributions of inputs of inner layers makes training less stable, leading to a decrease in the learning rate and slowing down of the training. Batch normalization mitigates this problem by standardizing the inputs of inner layers.
This explanation was harshly criticized by the next (2018) paper -- quoting the abstract:
... distributional stability of layer inputs has little to do with the success of BatchNorm
They demonstrate that BatchNorm only slightly affects the inner layer inputs distributions. More than that -- they tried to inject some non-zero mean/variance noise into the distributions. And they still got almost the same performance.
Their conclusion was that the real reason BatchNorm works was that...
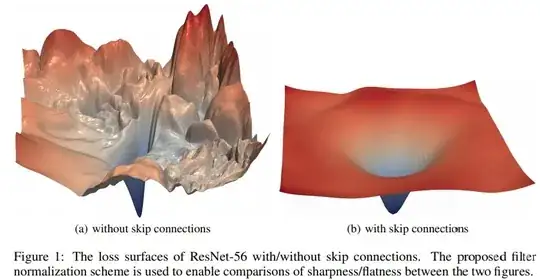
Instead BatchNorm makes the optimization landscape significantly smoother.
Which, to my taste, is slightly tautological to saying that it improves stability.
I've found two more papers trying to tackle the question: In this paper the "key benefit" is claimed to be the fact that Batch Normalization biases residual blocks towards the identity function. And in this paper that it "avoids rank collapse".
So, is there any bottom line? Why does BatchNorm work?