I'm currently reading the paper Likelihood Ratios for Out-of-Distribution Detection, and it seems that their problem is very similar to the problem of anomaly detection. More precisely, given a neural network trained on a dataset consisting of classes $A,B,$ and $C$, then they can detect if an input to the neural network is anomalous if it is different than these three classes. What is the difference between what they are doing and regular anomaly detection?
Asked
Active
Viewed 6,539 times
1 Answers
5
You observation is correct although the terminology needs a little explaining.
The term 'out-of-distribution' (OOD) data refers to data that was collected at a different time, and possibly under different conditions or in a different environment, then the data collected to create the model. They may say that this data is from a 'different distribution'.
Data that is in-distribution can be called novelty data. Novelty detection is when you have new data (i.e. OOD) and you want to know whether or not it is in-distribution. You want to know if it looks like the data you trained on. Anomaly detection is when you test your data to see if it is different than what you trained the model. Out-of-distribution detection is essentially running your model on OOD data. So one takes OOD data and does novelty detection or anomaly detection (aka outlier detection).
Below is a figure from What is anomaly detection?
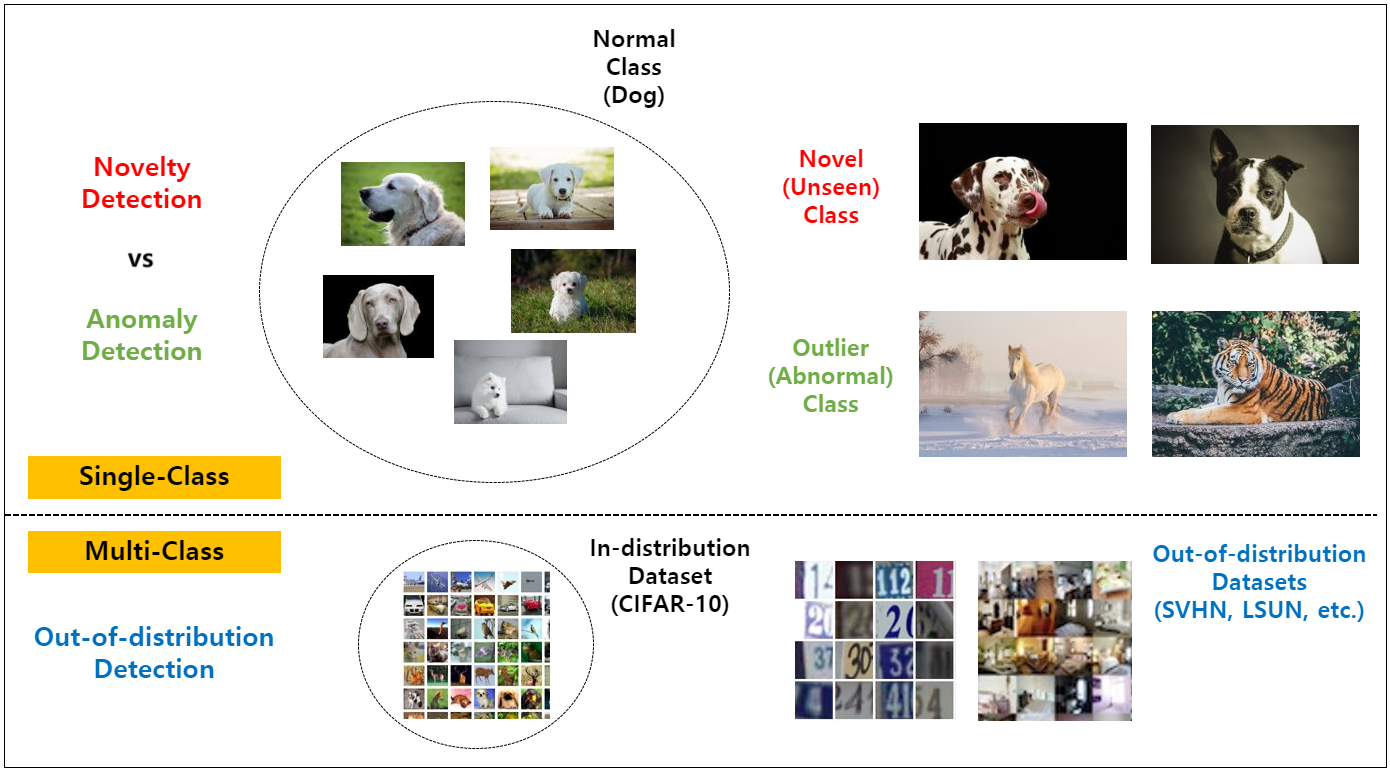
In time series modeling, the term 'out-of-distribution' data is analogous to 'out-of-sample' data and 'in-distribution' data is analogous with 'in-sample' data.
Brian O'Donnell
- 1,997
- 9
- 23