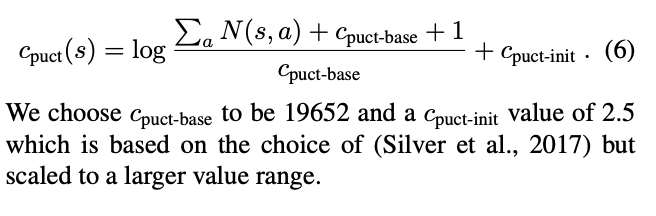I have a problem with applying alpha zero self-play to a game (Connect 6) with a huge branching factor (30,000 on average).
I have implemented the MCTS as described but I found that during the MCTS simulations for the first move, because P(s, a) is so much smaller than Q(s, a), the MCTS search tree is extremely narrow (in fact, it only had 1 branch per level, and later I have added dirichlet noise and it changed the tree to have 2 child branches instead of 1, per level).
With some debugging I figured that after the first simulation, the last visited child would have a Q value which is on average 0.5, and all the rest of the children would have 0 for their Q values (because they haven't been explored) while their U are way smaller, about 1/60000 on average. So comparing all the Q + U on the 2nd and subsequent simulations would result in selecting the same node over and over again, building this narrow tree.
To make matter worse, because the first simulation built a very narrow tree, and we don't clear the statistics on the subsequent simulations for the next move, the end result is the simulations for the first move dictated the whole self-play for the next X moves or so (where X is number of simulations per move) - this is because the N values on this path is accumulated from the previous simulations from the prior moves. Imagine I run 800 simulations per move but the N value on the only child inherited from previous simulations is > 800 when I started the simulation for the 3rd move in the game.
This is a basically related to question 2 raised in this thread:
AlphaGo Zero: does $Q(s_t, a)$ dominate $U(s_t, a)$ in difficult game states?
I don't think the answer addressed the problem I am having here. Surely we are not comparing Q and U but when Q dominates U then we ended up building a narrow and deep tree and the accumulated N values are set on this single path, preventing the self-play to explore meaningful moves.
At the end of the game these N values on the root nodes of moves played ended up training the policy network, reinforcing these even more on the next episode of training.
What am I doing wrong here? Or is AlphaZero algorithm not well suited for games with branching factor in this order?
Note: as an experiment I have tried to use a variable C PUCT value, which is proportional to the number of legal moves on each game state. However this doesn't seem to help either.