Contrastive learning is a framework that learns similar/dissimilar representations from data that are organized into similar/dissimilar pairs. This can be formulated as a dictionary look-up problem.
If I conceptually compare the loss mechanisms for:
Both MoCo and SimCLR use varients of a contrastive loss function, like InfoNCE from the paper Representation Learning with Contrastive Predictive Coding
\begin{eqnarray*}
\mathcal{L}_{q,k^+,\{k^-\}}=-log\frac{exp(q\cdot k^+/\tau)}{exp(q\cdot k^+/\tau)+\sum\limits_{k^-}exp(q\cdot k^-/\tau)}
\end{eqnarray*}
Here q is a query representation, $k^+$ is a representation of the positive (similar) key sample, and ${k^−}$ are representations of the negative (dissimilar) key samples. $\tau$ is a temperature hyper-parameter. In the instance discrimination pretext task (used by MoCo and SimCLR), a query and a key form a positive pair if they are data-augmented versions of the same image, and otherwise form a negative pair.
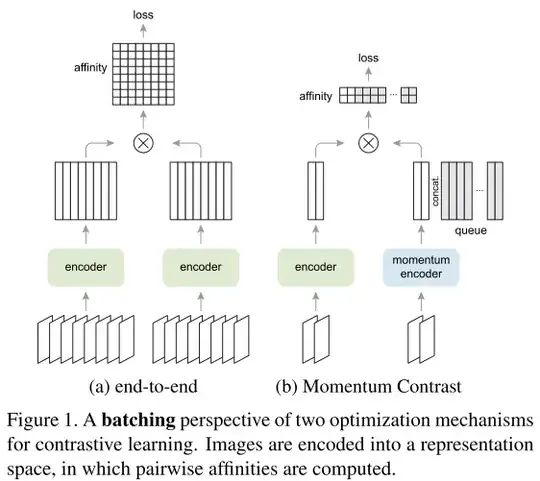
The contrastive loss can be minimized by various mechanisms that differ in how the keys are maintained.
In an end-to-end mechanism (Fig. 1a), the negative keys are from the same batch and updated end-to-end by back-propagation. SimCLR, is based on this mechanism and requires a large batch to provide a large set of negatives.
In the MoCo mechanism i.e. Momentum Contrast (Fig. 1b), the negative keys are maintained in a queue, and only the queries and positive keys are encoded in each training batch.
