The FaceNet model returns the loss of the predictions and ground-truth classes. How is this loss calculated?
Asked
Active
Viewed 486 times
1 Answers
6
The loss function used is the triplet loss function.
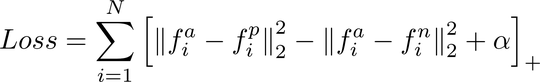 Let me explain it part by part.
Let me explain it part by part.
Notation
The $f^a_i$ means the anchor input image. The $f^p_i$ means the postive input image, which corresponds to the same people as the anchor image. The $f^n_i$ corresponds to the negative sample, which is a different person(input image) then the anchor image.
The formula explained step by step
The first part, $||f^a_i - f^p_i||^2_2$ basically calculates the distance between the anchor image output features and the postive image output features, which you want the distance to be as small as possible as the input is the same person. For the second part, $||f^a_i - f^n_i||^2_2$ , it calculates the distance of the output features of the anchor image and the negative image. You wnat the distance to be as large as possible as they are not the same person. Finally, the $\alpha$ term is a constant(hyperparameter) that adds to the loss to prevent negative loss.
How it works
The loss function optimizes for the largest distance between the anchor and negative sample and the smallest distance of the positive and anchor sample. It cleverly combines both metrics into one loss function. It can optimize for both case simultaneously in one loss function. If there is no negative sample, the model will not be able to differciate different person and vice versa.
Hope I can help you and have a nice day!
TheReal__Mike
- 121
- 8
Clement
- 1,755
- 9
- 24