TL;DR: Deep networks have some issues that skip connections fix.
To address this statement:
As I understand Resnet has some identity mapping layers that their task is to create the output as the same as the input of the layer
The residual blocks don't strictly learn the identity mapping. They are simply capable of learning such a mapping. That is, the residual block makes learning the identity function easy. So, at the very least, skip connections will not hurt performance (this is explained formally in the paper).
From the paper:
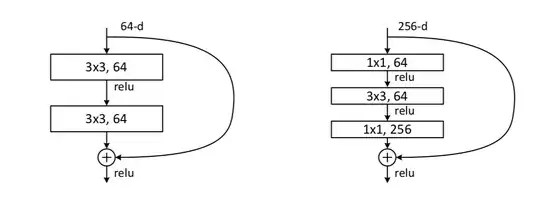
Observe: it's taking some of the layer outputs from earlier layers and passing their outputs further down and element wise summing these with the the outputs from the skipped layers. These blocks may learn mappings that are not the identity map.
From paper (some benefits):
$$\boldsymbol{y} = \mathcal{F}(\boldsymbol{x},\{W_i\})+\boldsymbol{x}\quad\text{(1)}$$The shortcut connections in Eqn.(1) introduce neither extra parameter nor computation complexity. This is not only attractive in practice but also important in our comparisons between plain and residual networks. We can fairly compare plain/residual networks that simultaneously have the same number of parameters, depth, width, and computational cost (except for the negligible element-wise addition).
An example of a residual mapping from the paper is $$\mathcal{F} = W_2\sigma_2(W_1\boldsymbol{x})$$
That is $\{W_i\}$ represents a set of i weight matrices ($W_1,W_2$ in the example) occurring in the layers of the residual (skipped) layers. The "identity shortcuts" are referring to performing the element wise addition of $\boldsymbol{x}$ with the output of the residual layers.
So using the residual mapping from the example (1) becomes:
$$\boldsymbol{y} = W_2\sigma_2(W_1\boldsymbol{x})+\boldsymbol{x}$$
In short, you take the output $\boldsymbol{x}$ of a layer skip it forward and element wise sum it with the output of the residual mapping and thus produce a residual block.
Limitations of deep networks expressed in paper:
When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error, as reported in [11, 42] and thoroughly verified by our experiments. Fig. 1 shows a typical example.
The skip connections and hence the residual blocks allow for stacking deeper networks while avoiding this degradation issue.
Link to paper
I hope this helps.
