This changes according to your data and complexity of your models. See following article by microsoft. Their conclusion is
The results suggest that the throughput from GPU clusters is always
better than CPU throughput for all models and frameworks proving that
GPU is the economical choice for inference of deep learning models.
...
It is important to note that, for standard machine learning models
where number of parameters are not as high as deep learning models,
CPUs should still be considered as more effective and cost efficient.
Since you are training MLP, it can not be thought as standard machine learning model. See my preprint, The impact of using large training data set KDD99 on classification accuracy. I compare different machine learning algorithms using weka.
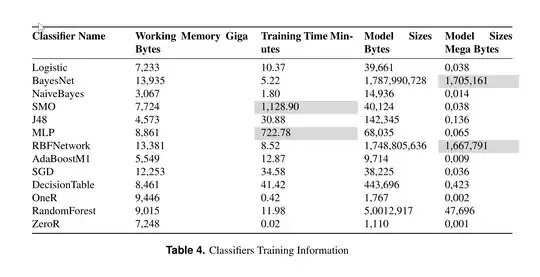
As you can see from above image, MLP takes 722 minutes to train while Naive Bayes ~2 minutes. If your data is small and your models parameters are not high, you will see better performance on CPU.