It seems like doing this would lead to much-needed nonlinearity, otherwise, we're just doing linear transformations.
Attention is broadly defined as a following operation ($\text{softmax}$ is sometimes replaced by $\tanh$) :
$$\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
Where $Q$, $K$ and $V$ are matrices that are some functions of the inputs.
There are three nonlinear operations there:
- The inner projection $QK^T$ is nonlinear. We have multiplication of two functions of the inputs. For example, in case of self-attention $Q=X W_Q$ and $K = XW_K$ are two linear transforms of the same $X$, so $QK^T = X \left(W_Q W_K^T\right) X^T$ is a quadratic function of the inputs.
- The $\text{softmax}(x_i) = e^{x_i} /\sum_n e^{x_n} $ function is obviously nonlinear ($\tanh$ as well)
- The final $\text{softmax}(\dots) V$ product is also nonlinear for the same reasons as (1)
I would say that it is pretty clear that it is definitely not just a linear transformation - there's quite a lot of nonlinearities in the attention block.
This observation applies to the transformer, additive attention, etc.
Let's see what happens next with the outputs of the attention layers:
In the transformer model, outputs of the multi-head-self-attention are fed into a feed-forward network inside each block:
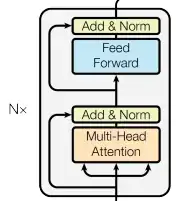
"Feed-forward" means that the inputs are multiplied by a weight matrix and then a nonlinear activation function is applied.
The additive attention approach, directly applies another $\text{softmax}$ on the outputs of what one would call the attention block:
$$e_{ij} = v_a^T \tanh\left(W_as_{i-1} + U_a h_j\right)$$
$$\alpha_{ij} = \frac{\exp(e_{ij})}{\sum_k \exp(e_{ik})}$$
To summarize - I don't think that the premise of the question is correct. Various nonlinearities are present both inside the attention blocks and, typically, are applied after the attention is computed.
