This is my first post so please forgive me for any mistakes.
I am working on an object detection algorithm that can detect abnormalities in an x-ray. As a prototype, I will be using yolov3 (more about yolo here: 'https://pjreddie.com/darknet/yolo/')
However, one radiologist mentioned that in order to produce a good result you need to take into account the demographics of the patient.
In order to do that, my neural network must take into account both text an an image. Some suggestions have been made by other people for this question. For example, someone recommended taking the result of a convolution neural network and a seperate text neural network.
Here is an image for clarification:
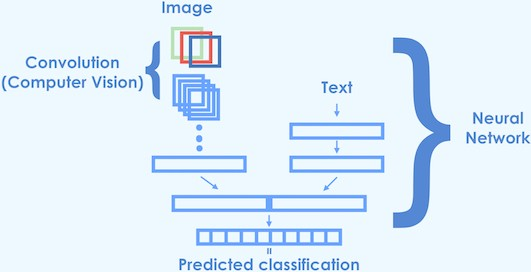
Image Credits: This image (https://cdn-images-1.medium.com/max/1600/1*oiLg3C3-7Ocklg9_xubRRw.jpeg) from Christopher Bonnett's article (https://blog.insightdatascience.com/classifying-e-commerce-products-based-on-images-and-text-14b3f98f899e)
For more details, please refer to above-mentioned article. It has explained how e-commerce products can be classified into various category hierarchies using both image and text data.
However, a when convolution neural network is mention it usssualy means it is used for classification instead of detection https://www.quora.com/What-is-the-difference-between-detection-and-classification-in-computer-vision (Link for comparison between detection and classification)
In my case, when I am using yolov3, how would it work. Would I be using yolov3 output vector which would be like this format class, center_x, center_y, width and height
My main question is how would the overall structure of my neural network be like if I have both image and text as input while using yolov3. Thank you for taking the time to read this.