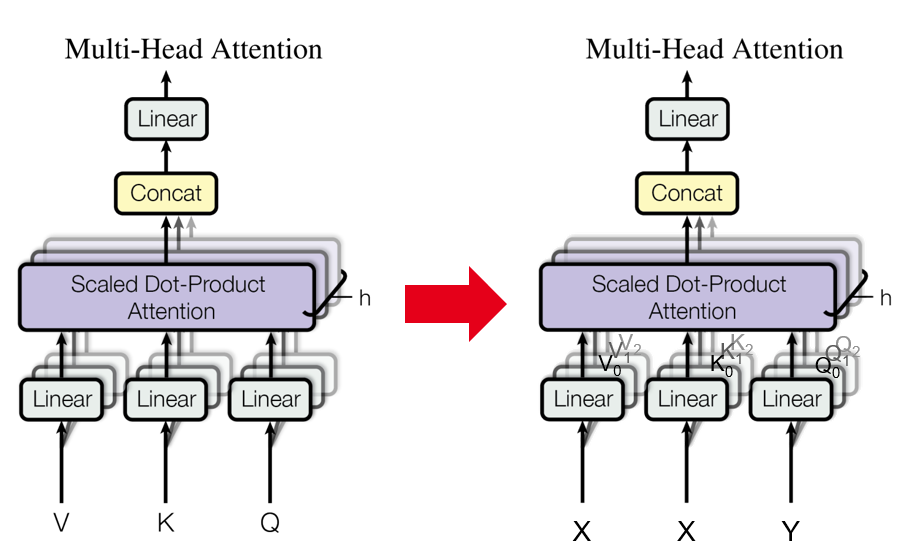
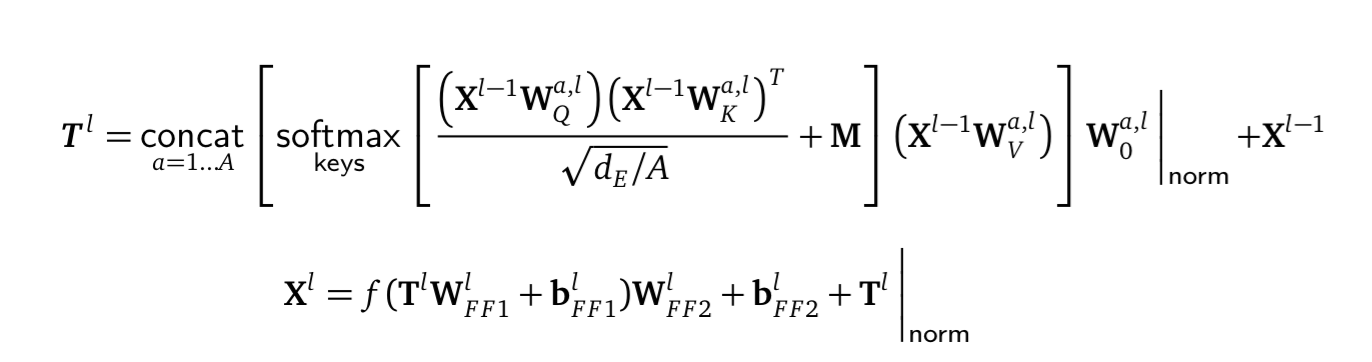The seminal Attention is all you need paper (Google Brain team, 2017) introduces Transformers and implements the attention mecanism with "queries, keys, values", in an analogy to a retrieval system.
I understand the whole process of multi-head attention and such (i.e., what is done with the $Q$, $K$, $V$ values and why), but I'm confused on how these values are computed in the first place. AFAICT, the paper seems to completely leave that out.
Both Figure 2 of the paper and equations explaining Attention and Multihead attention start with $Q$,$K$,$V$ already there :

The answers regaridng the origin of $Q$,$K$,$V$ I've found so far haven't satisfied me :
In this similar question, the accepted answer says "The proposed multihead attention alone doesn't say much about how the queries, keys, and values are obtained, they can come from different sources depending on the application scenario.". If this is the case, then why isn't the computing of $Q$,$K$,$V$ made more clear in the paper, at the very least for the task of language translation for which they show some numerical results and so obviously did compute $Q$,$K$,$V$ in some way ?
I also see some answers (eg this one on the same question) which say that $Q$, $K$, $V$ are the result of multiplication of the input embedding with some matrices $W$. This is also what is shown in the popular blog post The Illustrated Transformer :
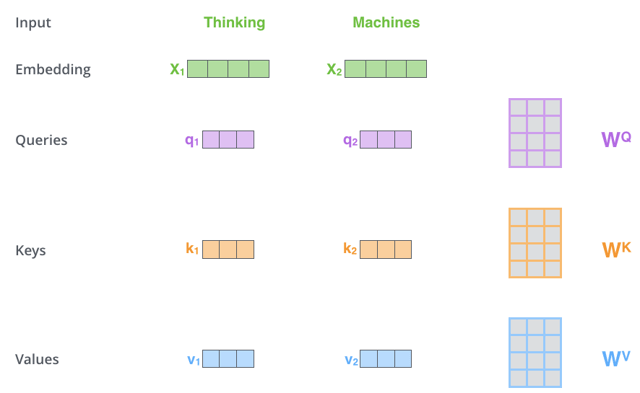
These "projection" matrices ($W^Q$, $W^K$, $W^V$) do seem to appear in the the definition of attention in the definition of $head_i$ (see top figure), but according to that equation, these matrices are multiplied by $Q$, $K$, $V$ (still appearing out of thin air, so the problem of their definition remains) and so the resulting product can't also be $Q$, $K$, $V$.
How are the $Q$, $K$, $V$ values computed ?